

Introduction
Approximate computing aims for efficient execution of workflows where an approximate output is sufficient instead of the exact output. Thus, approximate computing based on the chosen sample size — can make a systematic tradeoff between the output accuracy and computation efficiency. ApproxIoT is a stream analytics system to strike a balance between the two desirable but contradictory design requirements, i.e., achieving low latency for real-time analytics, and efficient utilization of computing resources.
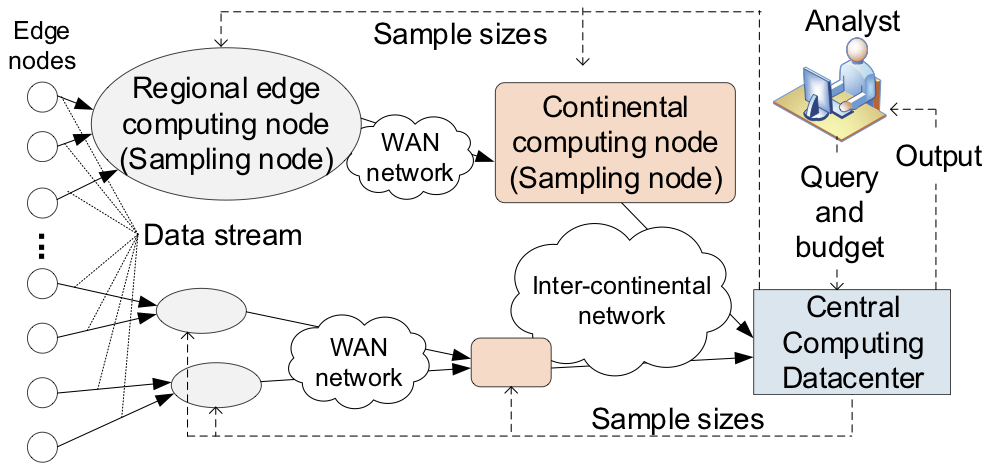
In this work, we implemented ApproxIoT using Apache Kafka and its library Kafka Streams to achieve a truly distributed data analytics system. An online stratified reservoir sampling algorithm was implemented on both Edge computing nodes and Datacenter cluster.
Source Code
The source code of ApproxIoT is available here